— Another way to query the definition of an object:
SELECT OBJECT_NAME(object_id), *
FROM sys.sql_modules
WHERE LOWER(DEFINITION) LIKE ‘%tbl%’
— Another way to query the definition of an object:
SELECT OBJECT_NAME(object_id), *
FROM sys.sql_modules
WHERE LOWER(DEFINITION) LIKE ‘%tbl%’
In computer networking, localhost (meaning this computer) is the standard hostname given to the address of the loopback network interface. This mechanism is useful for developers to test their software.
The default address for localhost is 127.0.0.1. This special IP address, also called the Loopback Address, is always defined to mean “the current machine”. It is not the same thing as the external IP address of your web server:
Localhost is configurable in the Hosts file (typically located at C:WindowsSystem32DriversEtcHosts). Due to multiple dependencies, it is usually not recommended to reconfigure it.
Instead, you can set up alternate domains in your Hosts file. For example, you could set
192.168.1.250 my.internal.website.com
192.168.1.249 your.internal.website.net
Internet Information Services (IIS) – is a web server software application created by Microsoft for use with Microsoft Windows.
If IIS is expecting a connection to IP address 192.168.1.250, then a connection to 127.0.0.1 will not match. When IIS responds to an HTTP request, it uses 3 pieces of information to figure out what web site it should use to build the response:
If your database has a very large table, you can “partition” this large table onto separate “filegroups.” Filegroups are special types of files that allows a user to divide data onto different disks for the purpose of optimizing query performance and maintenance operations. For example, say you have a tall file cabinet where you keep lists of customer names. As the number of files grow, the longer it takes to locate any given file. Database tables operate on the same principle.
The first thing you will need to do when planning out a partitioned table is to decide how you will divide the table up. As with our file cabinet example, we might decide to create one file cabinet where last names begin with A – F, another cabinet for files G – N, and another for files O – Z. Likewise, our table might also be divided up using last names as a way to organize. You can see how faster it would be to locate the last name “Jones” in one of three cabinets instead of a giant cabinet.
As business changes and data grows, partitioning can become more complicated; however, the example above does provide a basic understanding as to how partitioning can save time and resources.
Frequently, I get asked to explain a database design pattern involving “synonym-swapping.” Though I’m getting better at clarifying this approach, it is still often difficult for the business-side folks to really understand. I will now attempt to write a post to direct these people so that they do not have to listen to my ramblings.
First, database synonyms are a type of “alias”, or alternate name for a table, view, sequence, or other schema objects in a database. Some people refer to them as “pointers” because sometimes a synonym might point to one table and at another time it will point to a different table.
Synonyms are great ways of referencing one or more tables in your database. You can reference one or more tables by a single name. For example, say you had table that contained orders for your company. Your orders table has millions of rows and needs to be accessed 24-hours a day. However, what if updating the data in the table takes a couple of hours? Also, what if maintenance takes a few hours? Your users do not have the time to wait or suffer through a performance degradation. What will you do?
1. Create two tables that are exact duplicates of each other (“ORDERS_TABLE_A”, “ORDERS_TABLE_B”). Then create two synonyms, “Orders_Staging”,”Orders.” The “Orders” synonym will ALWAYS point to the table with the latest data.
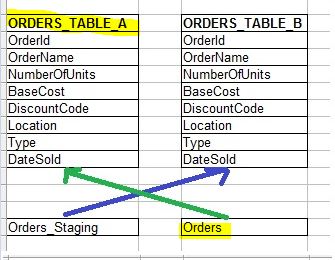
2. Say “Orders” is currently pointing to “ORDERS_TABLE_A” but the data needs refreshed. You will update “ORDERS_TABLE_B” then “swap” the synonym to point to “ORDERS_TABLE_B.” The time it takes to toggle a synonym between two tables is almost a split second. If something goes awry during the data refresh, then the synonyms never get swapped and the user has no interruption of service either way.
Synonyms are a very useful tool as it means that in your application does not have to worry about changing the table names from “ORDERS_TABLE_A” to “ORDERS_TABLE_B” and vice versa every time you do a refresh.
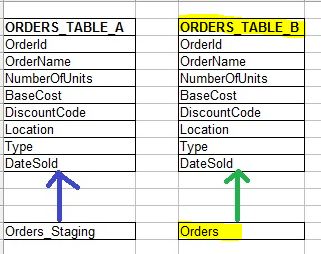
As you can see Synonyms are very useful tools for using aliases and can help when you have processes that involve building new tables to the side of existing ones for performance reasons.
For the sake of the more non-technical people, a database is a computer full of spreadsheets. Anytime you’ve looked at data in a grid-format, then you’ve looked at a spreadsheet at some point. For example, Microsoft Excel is the most popular spreadsheet software among office folks. Why do people use databases if they can just look at data in a spreadsheet? There are many of wonderful uses of databases, but the most necessary can be narrowed down to two: size and reporting.
SIZE
Data gets big very quickly. In Excel 2007, a user can enter 16,384 columns and 1,048,576 rows. This seems like allot of data! Your computer very well might crash if you tried to open an Excel spreadsheet containing a million rows, not to mention the amount of hard-drive space this would take!
A database is a dedicated piece of software created specifically for large amounts of data. Usually, a database will run on a computer that contains only databases.
REPORTING
Businesses operate on data. A business might use an Excel spreadsheet to keep track of the cost of office supplies. Another business might have to keep track a chain of store inventories s across the country and what inventory is in each store. They also might want to know what product sells more in the Midwest as opposed to the West Coast. Data is useless without a means to make sense of it all. Databases provide such means in a cost-effective and efficient manner. With proper setup, a query into a database can search through millions of rows to find the one piece of information that you want and do it in a matter of milliseconds.
Databases can be as simple or as complex as you can imagine. From cell phones to ATMs — all are dependent on data systems. The world runs on data. Now you know what I am referring to when I talk about databases.